Open sourcing the AI proxy
Last week, we released the Braintrust AI Proxy, a new, free way to access LLaMa2, Mistral, OpenAI, Anthropic, and many other models behind the OpenAI protocol with built-in caching and API key management.
Folks immediately started reaching out about running the proxy in production. We firmly believe that code on the critical path to production should be open source, so we're excited to announce that the proxy's source code is now available on GitHub (opens in a new tab) under the MIT license (opens in a new tab).
Deployment options
You can continue to access the proxy, for free, by using the hosted version at https://braintrustproxy.com. It's hosted
on Cloudflare workers (opens in a new tab) and end-to-end encrypts cached data using 256-bit AES-GCM encryption.
For more details, see the documentation or source code (opens in a new tab).
The repository also contains instructions (opens in a new tab) for deploying the proxy to Vercel Edge Functions (opens in a new tab), Cloudflare workers (opens in a new tab), AWS Lambda (opens in a new tab), or as a plain-old Express server (opens in a new tab).
Benchmarks
I did some quick benchmarks, from my in-laws' place in California and an EC2 machine (US East N. Virginia) to compare performance across options (code (opens in a new tab)).
The AWS Lambda functions are deployed in us-east-1. aws-pc is AWS Lambda with provisioned concurrency (opens in a new tab).
In-laws (CA)
$ python proxy_benchmark.py -n 100
cloudflare: AVG: 57.98ms, MIN: 42.39ms, MAX: 258.04ms
vercel: AVG: 82.05ms, MIN: 54.65ms, MAX: 326.60ms
aws: AVG: 131.95ms, MIN: 103.64ms, MAX: 722.90ms
aws-pc: AVG: 145.10ms, MIN: 109.22ms, MAX: 1704.05msEC2 (US East N. Virginia)
$ python proxy_benchmark.py -n 100
cloudflare: AVG: 32.23ms, MIN: 20.15ms, MAX: 283.90ms
vercel: AVG: 55.72ms, MIN: 25.03ms, MAX: 512.94ms
aws: AVG: 43.91ms, MIN: 22.20ms, MAX: 130.78ms
aws-pc: AVG: 68.13ms, MIN: 24.46ms, MAX: 973.50msAs you can see, Cloudflare and Vercel are consistently very fast, and AWS Lambda in US East suffers (as expected) when measured from CA. I was surprised that AWS Lambda with provisioned concurrency was slower than without. Perhaps I misconfigured something...
Additional features
Along with the open source release, the proxy contains a number of useful built-in features.
Caching
The proxy automatically caches responses from the model provider if you set a seed value or temperature=0.
Seeds are a new feature in the OpenAI API that allows you to create reproduceable results, but most model providers
do not yet support them. The proxy automatically handles that for you.
API key management
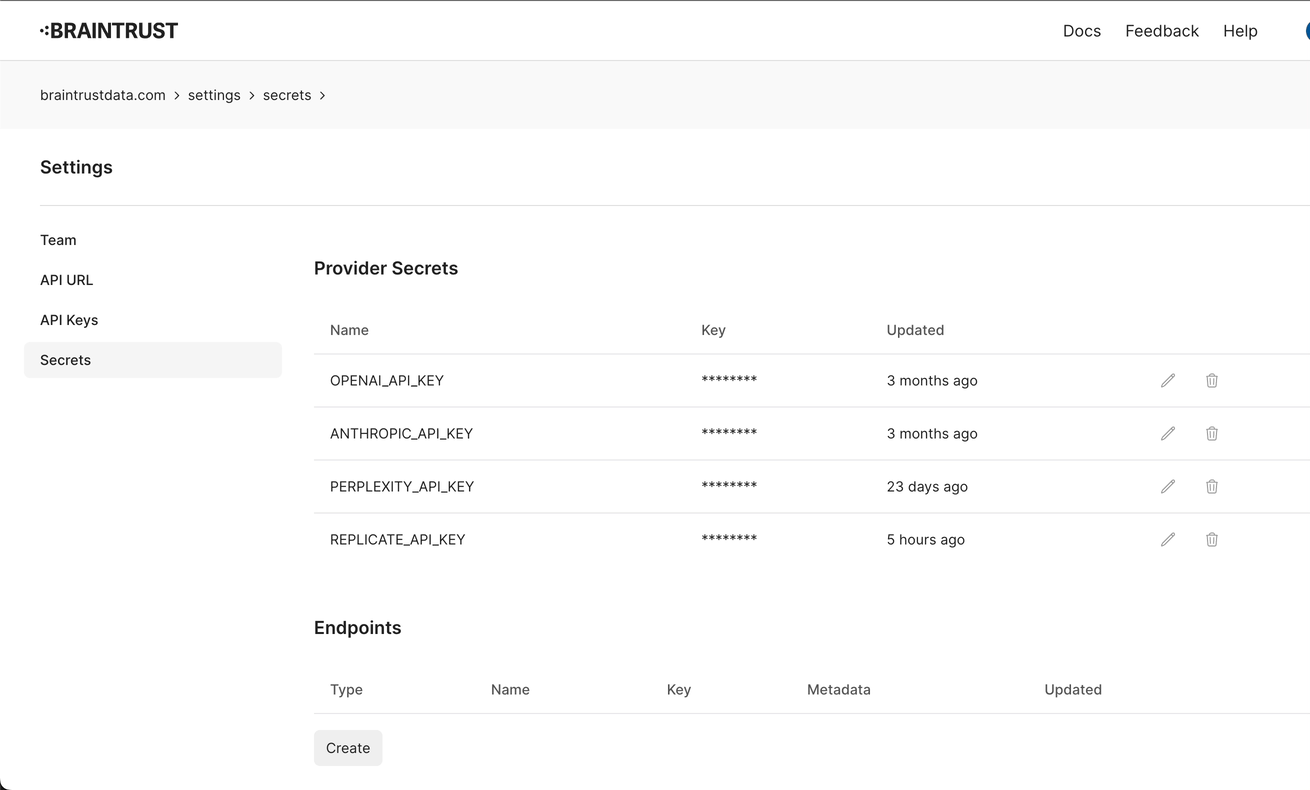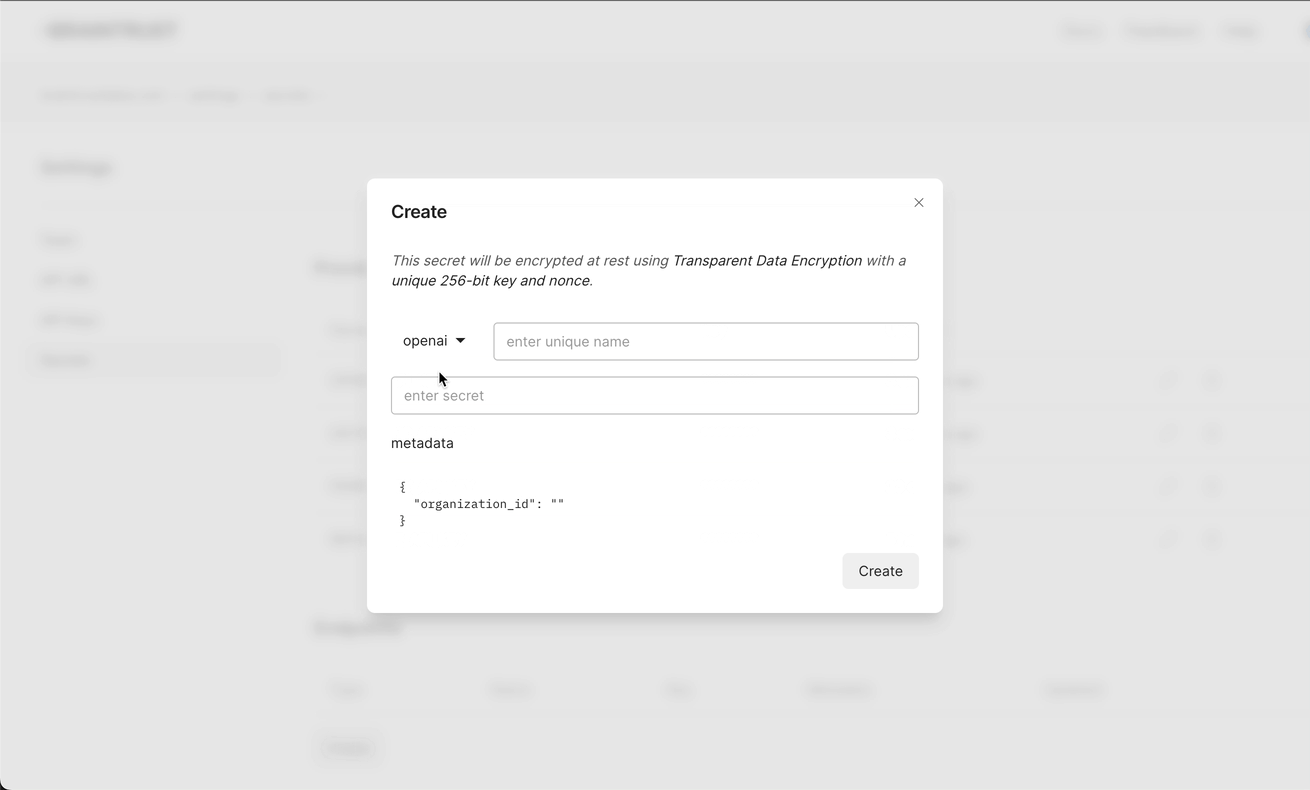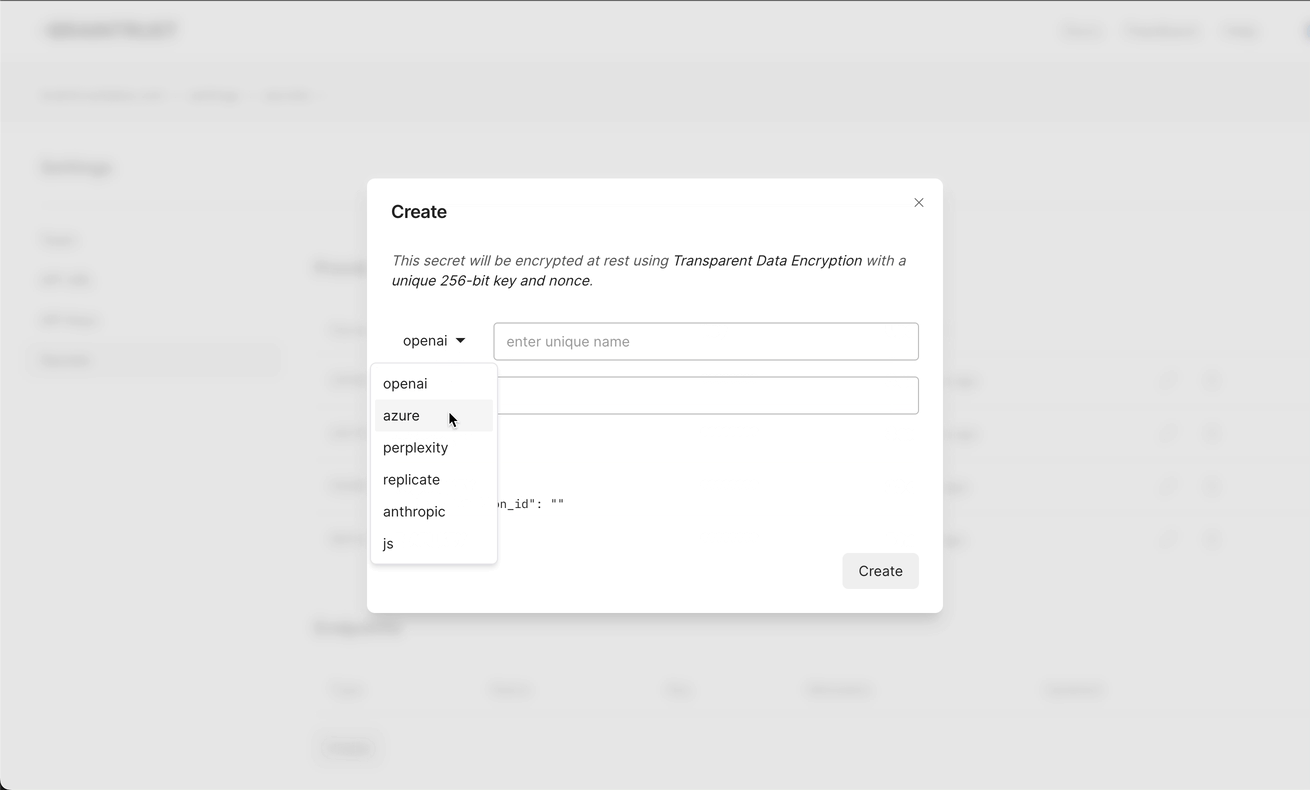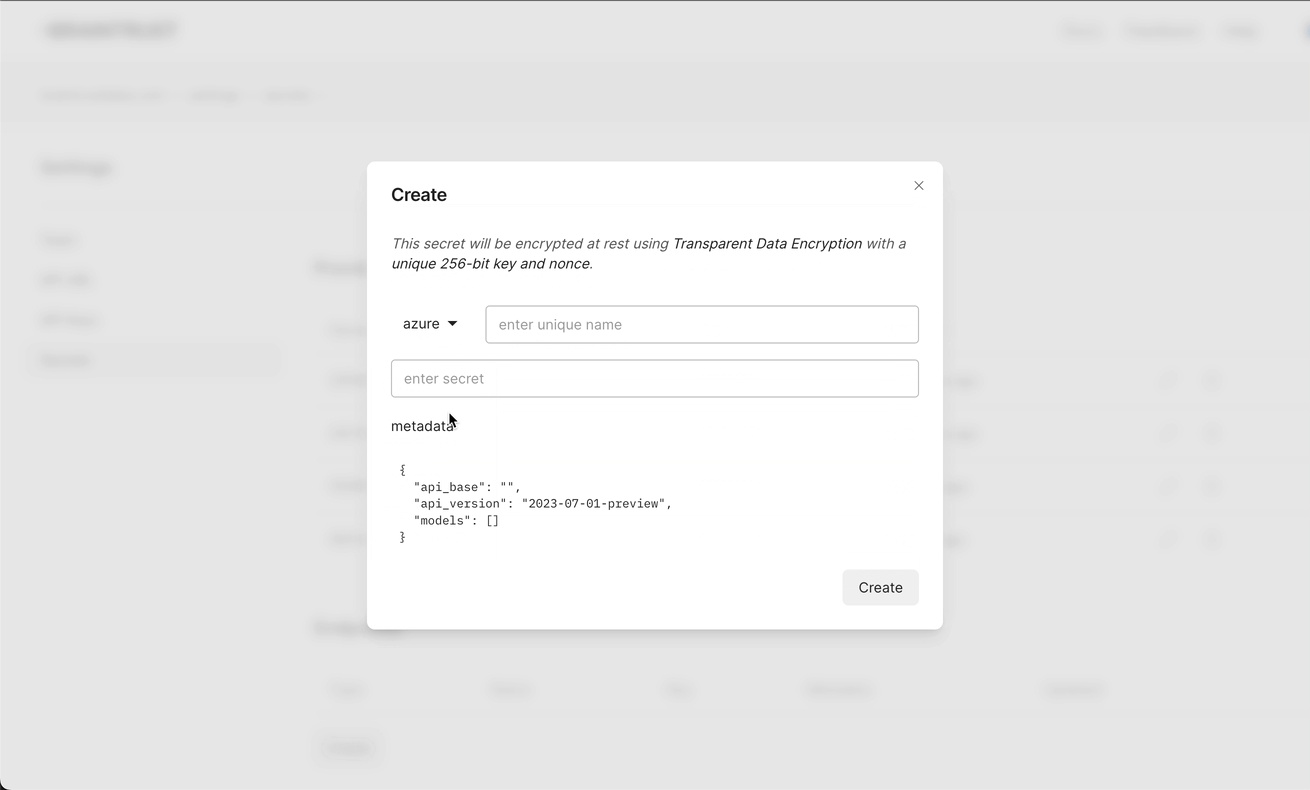
You can add API keys across providers as secrets in Braintrust, and use a single API key to access all of them. This is a great way to manage your API keys in one place, and share them with your team.
Load balancing
You can now add multiple keys and organizations as secrets in Braintrust, and the proxy will automatically load balance across them for you. This is a simple way to add resiliency across OpenAI accounts or providers (e.g. OpenAI and Azure).
Azure OpenAI
You can access Azure's OpenAI endpoints through the proxy, with vanilla OpenAI drivers, by configuring Azure endpoints in Braintrust. If you configure both OpenAI and Azure endpoints, the proxy will automatically load balance between them.
Replicate Lifeboat
We now support the Replicate lifeboat (opens in a new tab) meta/llama-2-70b-chat model, including tool use,
as an option. Simply enter your Replicate API key in Braintrust
to get started.
What's next
We have an exciting roadmap ahead for the proxy, including more advanced load balancing/resiliency features, support for more models/providers, and deeper integrations into Braintrust.
If you have any feedback or want to collaborate, send us an email at info@braintrustdata.com or join our Discord (opens in a new tab).