Logging
This guide walks through how to log real-world interactions in your application. We encourage you to use the feature to track user behavior, debug customer issues, and incorporate new patterns into your evaluations. Ultimately, logging effectively is a critical component to developing high quality AI applications.
Before proceeding, make sure to read the quickstart guide and setup an API key.
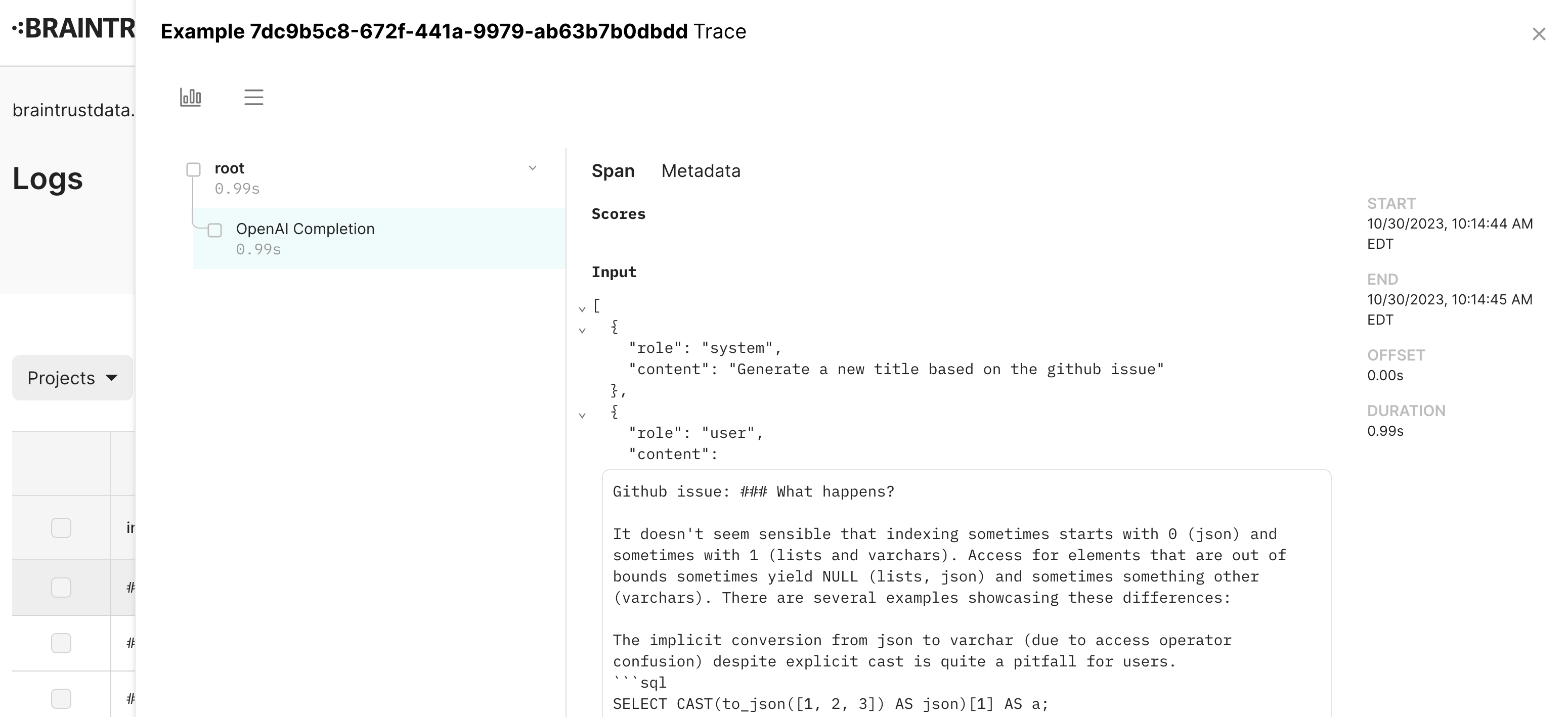
Traces: the building block of logs
The core building blocks of logging are spans and traces. A span represents a unit of work, with a start and end time, and optional fields like input, output, metadata, scores, and metrics (the same fields you can log in an Experiment). Each span contains one or more children, which are usually run within their parent span (e.g. a nested function call). Common examples of spans include LLM calls, vector searches, the steps of an agent chain, and model evaluations.
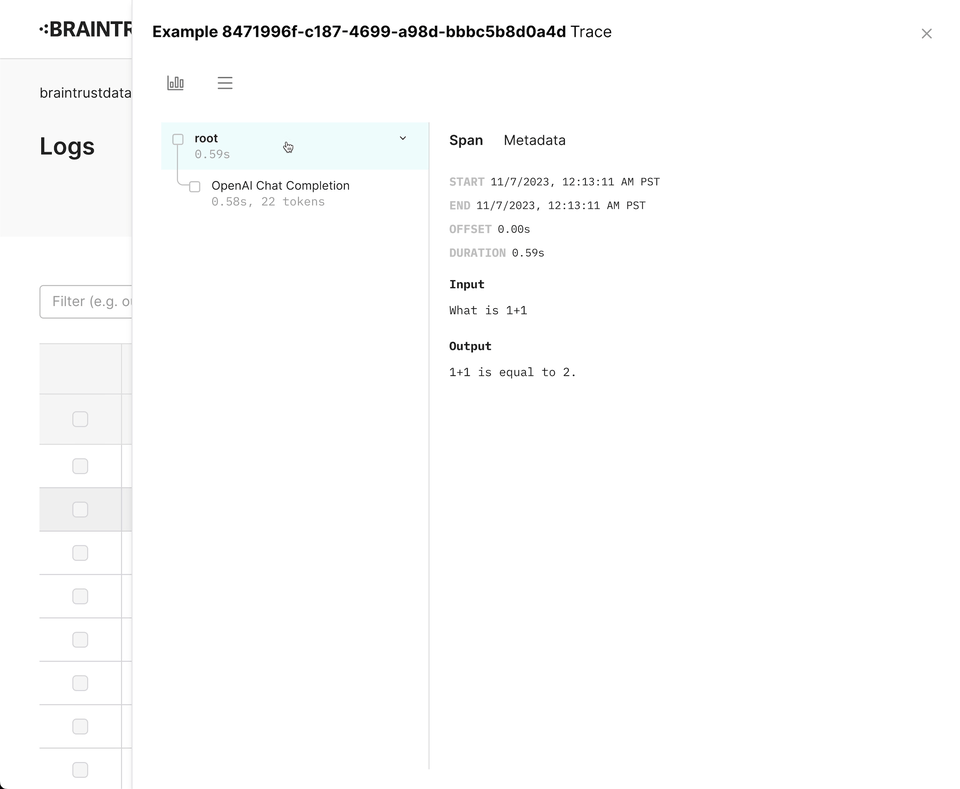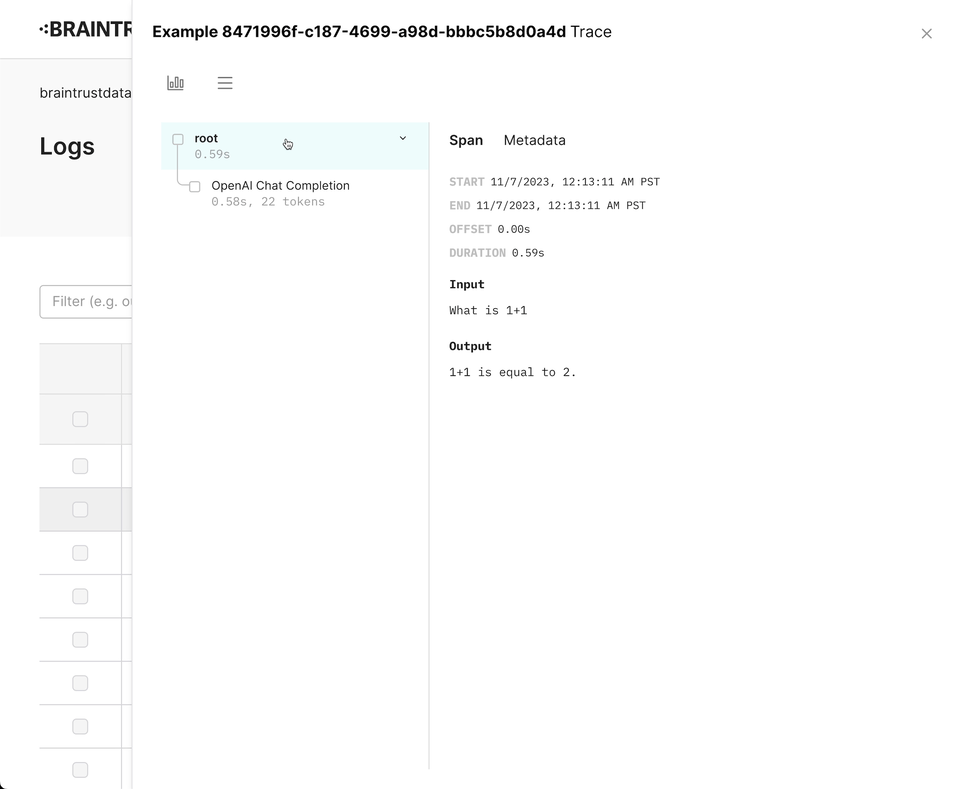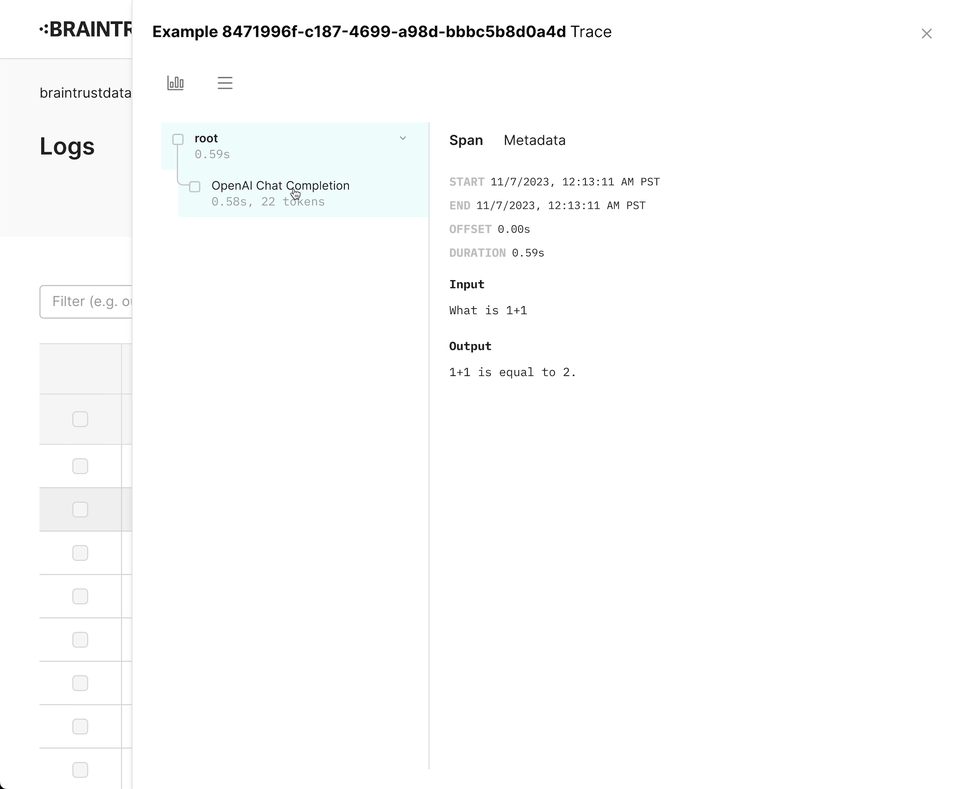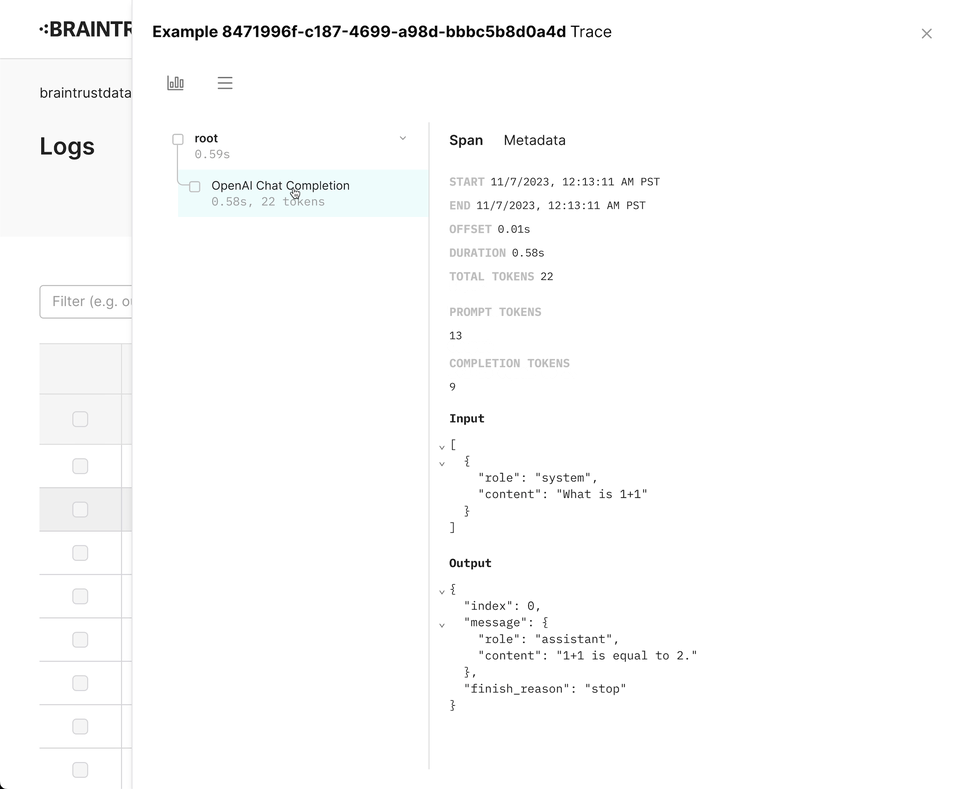
Together, spans form a trace, which represents a single independent request. Each trace is visible as a row in the logs table. Well-designed traces make it easy to understand the flow of your application, and to debug issues when they arise. The rest of this guide walks through how to log rich, helpful traces.
A trace is usually a tree of spans; however, Braintrust technically supports any arbitrary graph structure.
Annotating your code
To log a trace, you simply wrap the code you want to trace. Braintrust will automatically capture and log information behind the scenes.
import { initLogger } from "braintrust";
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
export async function POST(req: Request) {
return logger.traced(async (span) => {
const { body } = req;
const result = await someLLMFunction(body);
span.log({ input: body, output: result });
return result;
});
}Wrapping OpenAI
Braintrust includes a wrapper for the OpenAI API that automatically logs your requests. To use it, simply
call wrapOpenAI/wrap_openai on your OpenAI instance. We intentionally do not monkey patch (opens in a new tab)
the libraries directly, so that you can use the wrapper in a granular way.
import { OpenAI } from "openai";
import { initLogger, wrapOpenAI } from "braintrust";
const openai = wrapOpenAI(
new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
);
const logger = initLogger({
projectName: "My Project",
apiKey: process.env.BRAINTRUST_API_KEY,
});
export async function POST(req: Request) {
return logger.traced(async (span) => {
const { body } = req;
const result = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: body }],
});
span.log({
input: body,
output: result.choices[0]?.message.content,
metadata: { user_id: req.user.id },
});
return result;
});
}
Deeply nested code
Often, you want to trace functions that are deep in the call stack, without having to propagate the span
object throughout. Braintrust uses async-friendly context variables to make this workflow easy:
- The
currentSpan()/current_span()method returns the currently active span. - In Python, the
traceddecorator automatically wraps your function in a span.
import { currentSpan, initLogger } from "braintrust";
const logger = initLogger();
export async function runLLM(input) {
return await currentSpan().traced("LLM call", async (span) => {
const result = await someLLMFunction(input);
span.log({
input,
output: result.content,
metrics: {
tokens: result.tokens,
},
});
return result;
});
}
export async function someLogic() {
return await runLLM("You are a magical wizard. Answer the following question: " + input);
}
export async function POST(req) {
return await logger.traced(async () {
return await someLogic(req.body);
});
}If Braintrust is not initialized or there is no active logger, then the current span will be a no-op and your code will execute as normal, with negligible performance overhead.
Viewing logs
Logs are updated in real-time as new tracees are logged. You can filter logs by time range or arbitrary subfields.
Implementation considerations
Data model
- Each log entry is associated with an organization and a project. If you do not specify a project name or id in
initLogger()/init_logger(), the SDK will create and use a project named "Global". - Although logs are associated with a single project, you can still use them in evaluations or datasets that belong to any project.
- Like evaluation experiments, log entries contain optional
input,output,expected,scores,metadata, andmetricsfields. These fields are optional, but we encourage you to use them to provide context to your logs. - Logs are indexed automatically to enable efficient search. When you load logs, Braintrust automatically returns the most recently
updated log entries first. You can also search by arbitrary subfields, e.g.
metadata.user_id = '1234'. Currently, inequality filters, e.g.scores.accuracy > 0.5do not use an index.
Initializing
The initLogger()/init_logger() method initializes the logger. Unlike the experiment init() method, the logger lazily
initializes itself, so that you can call initLogger()/init_logger() at the top of your file (in module scope). The first
time you log() or start a span, the logger will log into Braintrust and retrieve/initialize project details.
Flushing
The SDK can operate in two modes: either it sends log statements to the server after each request, or it buffers them in
memory and sends them over in batches. Batching reduces the number of network requests and makes the log() command as fast as possible.
Each SDK flushes logs to the server as fast as possible, and attempts to flush any outstanding logs when the program terminates.
You can enable background batching by setting the asyncFlush / async_flush flag to true in initLogger()/init_logger().
When async flush mode is on, you can use the .flush() method to manually flush any outstanding logs to the server.
// In the JS SDK, `asyncFlush` is false by default.
const logger = initLogger({ asyncFlush: true });
...
// Some function that is called while cleaning up resources
async function cleanup() {
await logger.flush();
}Serverless environments
The asyncFlush / async_flush flag controls whether or not logs are flushed
when a trace completes. This flag should be set to false in serverless environments where the process
may halt as soon as the request completes. By default, asyncFlush is set to false in the Typescript SDK, since
most Typescript applications are serverless, and True in Python.
const logger = initLogger({
asyncFlush: false,
});